引入
Q Learning 是强化学习的一种实现。
强化学习是让计算机从不懂到懂,通过不断尝试从错误中学习找到规律最终达到目的算法。通过奖励与惩罚的方式计算机可以不断摸索,可以说就是不断积累经验的过程。
我们首先引入一个一维迷宫。假设有 6 个块,其中一个块有宝藏。有一个计算机探险者,它不知道哪里有宝藏,只能选择向左或向右,要如何才能让探险者更快地找到宝藏呢?
|
|
这里 O 是探险者,T 是宝藏,- 是空白块。
我们使用 Python 实现这个过程。
代码放在 Github 仓库,需要的自取:
treasure_on_right.py
Q Learning 介绍
Q Learning 通过 Q 表存储每一块可能决策的收益。依据 Q 表来进行动作的选择,并在每一次选择后计算收益以更新 Q 表。
通过 Q 表可以计算当前的最优策略。Q表存储的是对各种动作收益的历史经验,是一种预期。而根据预期做出决策后会得到实际收益,实际收益与预期很多时候不相符,这时就需要更新历史经验了,即更新Q表(预期收益)。
算法的计算主要有两部分:
- 动作选择
- 更新 Q 表
对于 Q Learning 有一些量是需要介绍的:
- 动作(ACTIONS) :动作是计算机可以做出的决策
- 理性值(EPSILON) :对于动作选择中,作为随机或依据 Q 表的参考量
- 学习率(ALPHA) :更新 Q 表时当前值的累加的权重
- 折扣因子(GAMMA) :衡量未来奖励有多重要(有两个计算量分别是预期收益和实际收益,通过折扣因子表示两者对目标的权重)
动作选择算法
上文提到有理性值 EPSILON ,假设理想值为 0.9 说明有 90 % 的可能我们选择理性,而剩下的 10 % 就交给概率决定选择的动作。
当然,当在最初计算机没有任何经验的时候也会通过随机选择动作来打破僵局。
收益计算
当我们做出动作选择后,我们会进行收益的计算。当实际收益与预期收益有差时,我们就更新 Q 表.
对于 Q 表更新值有:
$Q表新值 = Q表旧值 + 学习率 \times (实际收益 - 预期收益)$
显然当 $实际收益 - 预期收益 \neq 0$ 时会进行 Q 表更新。
对于收益计算简单来说有两种可能:下一步得到奖励或下一步没有奖励。
当下一步是终点
此时预期收益等于 Q 表当前值
实际收益等于 1,即得到奖励
当下一步不为终点
这个是一般情况,我们要继续计算收益。
预期收益还是 Q 表当前值。
$实际收益=奖励+未来预期最大收益 \times 折扣因子$
当实际收益和预期收益有差时更新 Q 表。
在对 Q Learning 基本阐述后,我们使用 python 绘制一维迷宫来实现 Q Learning 算法。
使用的 Python 库
|
|
这里使用到两个数学数据分析相关的模块numpy, pandas。
除此之外还有相关内置库 time os。
函数功能介绍
-
def rl()这是整个程序的主体函数,在这里创建 Q 表,进行几轮的模拟最终可以得到不错的 Q 表 -
def build_q_table(n_states, actions)初始化 Q 表 -
def choose_action(state, q_table)对每一次移动做出抉择 -
def get_env_feedback(S, A)得到下一步位置和是否获得奖励 -
def update_env(S, episode, step_counter)更新环境,进行一些输出的绘制
RL 函数——程序主体
我们知道,该代码核心调用是 rl() 函数,
展示一下该函数:
|
|
有一说一,pandas 模块的 DataFrame 数组确实挺好用的,就连列表打印都那么可视化!可谓难得。
q_table 在整个函数周期都存在,不会因为每一轮变化而重新初始化。 MAX_EPISODES 为训练的总回合数,在 for 循环里很明了。
又是几个变量说明:(有点烦)……
step_counter计数器,计算每一回合的步数,可以从中看到强化学习的效果S初始位置(用大写变量差评)is_terminated是否达到终点的标志,也就是 while 循环的结束条件,作用就是方便跳出 while 循环
后面还有一些比较"局部"的变量(python 可没有局部全局这种实际的说法)也就逐一介绍吧:A当前的行动S_我们下一个状态,类型是个字符串或整形(python 是这样的)。R奖励,这里只有 0 或 1q_predict预期收益q_target实际收益
下面逐行解释下 while 循环内单个回合的过程:
|
|
首先我们通过 choose_action(S, q_table) 获得下一步的行动。此时位置变量 S 还没有改变。将下一步行动先给变量 A
|
|
读下一个位置的 Q 表获得预期收益。
|
|
获得下一步的位置索引和奖励
接下来是实际收益的计算: 上文知道,我们需要判断下一步是否为终点来确定我们实际收益的计算方法整体代码如下:
|
|
需要简单提下
S_变量到底会存储啥。
S_可能会有两种数据类型的可能(天哪,也就只有 python 可以这样做了!🥺)int 或者 str
在get_env_feedback(S, A)里,如果下一步是终点直接返回"terminal"这个字符串,否则就返回下一步的位置。(python 字符串类型太好用了不是)
这里比较抽象的是 q_table.iloc[S_, :].max() , python 有非常多语法糖,这是其中一个。一般来说在 python : 符号用于切片,而单独的 : 就是取出全部数据。
iloc() 方法用于根据索引访问数据,然后通过链式调用给 max() 取出两个数据的最大值。这里体现了贪心思想。
整个条件判断就是上文讲的实际收益。
|
|
通过增量式的计算更新 Q 表。
|
|
实际更新位置变量
|
|
一些自己补充用于更好展现 Q 表更新的代码。不解释了(
|
|
返回最终的 Q 表
至此,rl 函数就解释完了。整个 Q Learning 核心逻辑也基本解释差不多了。
choose_action(state, q_table) 函数——动作选择函数
|
|
返回值 action_name 是 ACTIONS 列表里的一个值,应该是 str 类型。
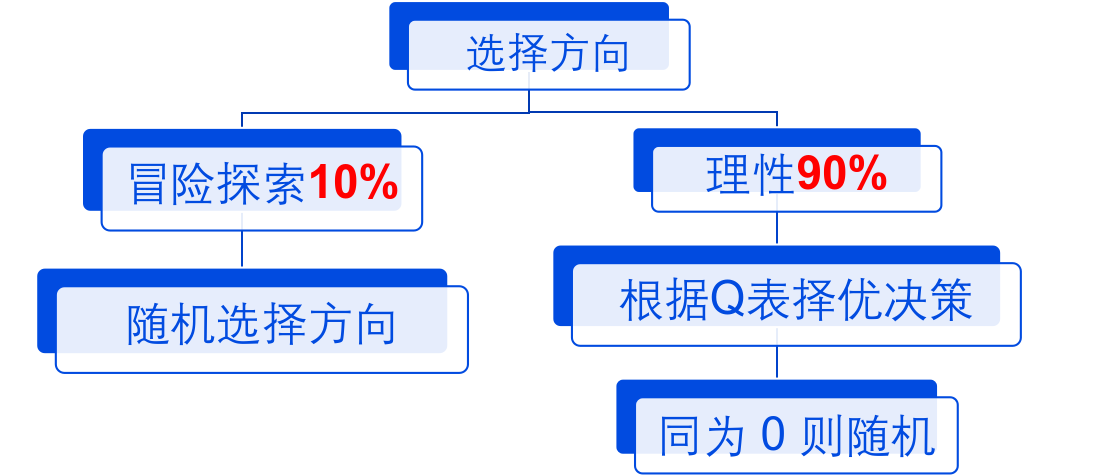
当 EPSILON = 0.9 对于动作选择函数有:
|
|
这里的 state_actions 保存了两个值:Q 表该元素的 left 和 right。
对于动作选择函数主要区分是否选择冒险探索的判断条件:
|
|
有些许抽象
numpy.random.uniform() 是生成一个随机数,默认没有参数时生成随机数范围为 [0, 1)。刚好可以符合概率要求
显然当生成的随机数大于 EPSILON 的可能性为 10% 符合冒险探索的可能
除此之外,当该块的 Q 表左右两个值都为 0,也就是还没有得到收益时候也应该进行冒险探索,条件为 ((state_actions == 0).all()) 也蛮不好理解的……
(state_actions == 0) 是布尔值,传参到 all() 方法就是 state_actions 两个数据(left 和 right) 都为 0 时为真(python 面向对象还在发挥)。这样就能判断出在最初没有实际收益时的情况。
让我们深入去了解(这个函数逻辑好理解,就是用了很多抽象的 python 语法)
- 当 if 成立也就是进行冒险探索时,我们执行该函数:
|
|
它随机从 ACTIONS 中选取一个值给 action_name 作为我们下一步行动的方向
2. 当 if 不成立,执行 else 语句进入理性选择
|
|
直接选择最大值的索引标签为返回值。在初始化时 pandas.DataFrame 数据类型可以指定索引标签(抽象++)。
至此,动作选择算法函数就差不多了。
build_q_table(n_states, actions) Q 表的初始化
Q 表(q_table) 用的是 pandas 模块的 DataFrame 数据类型。
|
|
DataFrame 数据类型太强大了(强大到我都看晕了)。这里给出它的构造方法。
|
|
我们这里只用到了两个参数,第一个为默认第一个参数 data, 直接用 numpy 初始化一个 n_states 行 actions 列的二维数组。
然后第二个参数是 columns (不是默认第二个参数。),将列的索引标签写为 actions 值。
最后返回创建的表格。
get_env_feedback(S, A) 获取下一步的位置和奖励
这个函数比较简单,没有那么多抽象的语法。
|
|
形参 A 其实在 rl() 是 通过 choose_action 选择的动作。这里通过判断下一步的动作获得下一步的位置和奖励。如果此时下一步位置为右,而且当前位置在奖励左边,则可以判断出奖励为 1。这个函数其实仔细研究下就能懂。
这里要特判在第一个位置也就是 S = 0 时是不能往右走的。
注意的是这里的返回:return S_, R 返回了两个参数,在调用也要用两个参数接收,在 rl() 函数中接收。
update_env(S, episode, step_counter) 输出信息
这个函数输出了当前迷宫的情况以及一些位置的
|
|
先初始化一个迷宫图,这时候没有探索者,特判如果已经达到了奖励位置则输出回合数和和该回合数的步数。
|
|
这里 print() 函数格式化,同时把默认后置换行取消掉(将 end="", 默认 end="\n")。
如果没有奖励,则将位置所代表的索引字符串表替换成 o 代表探索者。
后面七七八八的不详细说了,都差不多。
其他代码
|
|
代码开始的 numpy 随机数种子
|
|
程序入口
实际示例
第一回合结束:
|
|
第二回合结束:
|
|
第四回合结束:
|
|
到这时候只需要 5 步就能走到了
最后:
|
|
到最后基本上可以一路向右直接走到终点不带犹豫的。